On this recurring month-to-month characteristic, we filter current analysis papers showing on the arXiv.org preprint server for compelling topics regarding AI, machine studying and deep studying – from disciplines together with statistics, arithmetic and laptop science – and offer you a helpful “better of” listing for the previous month. Researchers from all around the world contribute to this repository as a prelude to the peer assessment course of for publication in conventional journals. arXiv comprises a veritable treasure trove of statistical studying strategies chances are you’ll use someday within the answer of knowledge science issues. The articles listed under signify a small fraction of all articles showing on the preprint server. They’re listed in no specific order with a hyperlink to every paper together with a short overview. Hyperlinks to GitHub repos are offered when obtainable. Particularly related articles are marked with a “thumbs up” icon. Contemplate that these are tutorial analysis papers, sometimes geared towards graduate college students, submit docs, and seasoned professionals. They typically comprise a excessive diploma of arithmetic so be ready. Take pleasure in!
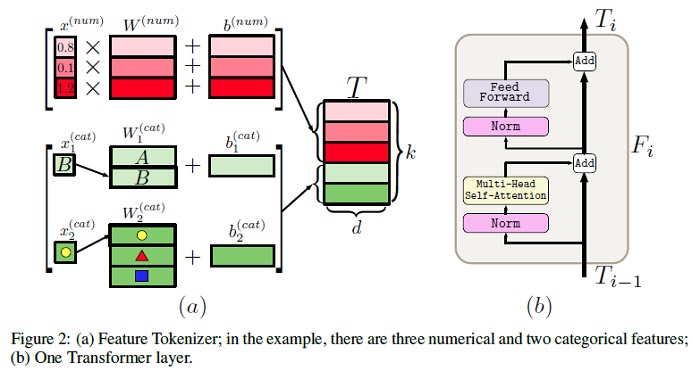
The need of deep studying for tabular information continues to be an unanswered query addressed by a lot of analysis efforts. The current literature on tabular DL proposes a number of deep architectures reported to be superior to conventional “shallow” fashions like Gradient Boosted Resolution Timber. Nonetheless, since current works usually use completely different benchmarks and tuning protocols, it’s unclear if the proposed fashions universally outperform GBDT. Furthermore, the fashions are sometimes not in contrast to one another, due to this fact, it’s difficult to establish the perfect deep mannequin for practitioners. This paper begins with an intensive assessment of the principle households of DL fashions just lately developed for tabular information. The authors rigorously tune and consider them on a variety of datasets and reveal two vital findings. First, it’s proven that the selection between GBDT and DL fashions extremely will depend on information and there’s nonetheless no universally superior answer. Second, it’s demonstrated {that a} easy ResNet-like structure is a surprisingly efficient baseline, which outperforms many of the refined fashions from the DL literature. Lastly, the authors design a easy adaptation of the Transformer structure for tabular information that turns into a brand new sturdy DL baseline and reduces the hole between GBDT and DL fashions on datasets the place GBDT dominates. The GitHub repo related to this paper will be discovered HERE.
Whereas a lot hype has been produced concerning the speedy tempo of enterprise cloud deployments, in actuality we estimate lower than 25 % of enterprise workloads are at the moment being run within the cloud. That doesn’t negate the significance of the expansion of cloud computing – however it does set some parameters round simply how prevalent it at the moment is, and the way troublesome it's to maneuver enterprise workloads to a cloud structure.
Tabular information underpins quite a few high-impact purposes of machine studying from fraud detection to genomics and healthcare. Classical approaches to fixing tabular issues, corresponding to gradient boosting and random forests, are broadly utilized by practitioners. Nonetheless, current deep studying strategies have achieved a level of efficiency aggressive with well-liked methods. This paper devises a hybrid deep studying method to fixing tabular information issues. The proposed methodology, SAINT, performs consideration over each rows and columns, and it contains an enhanced embedding methodology. The paper additionally research a brand new contrastive self-supervised pre-training methodology to be used when labels are scarce. SAINT constantly improves efficiency over earlier deep studying strategies, and it even outperforms gradient boosting strategies, together with XGBoost, CatBoost, and LightGBM, on common over quite a lot of benchmark duties. The GitHub repo related to this paper will be discovered HERE.
The analysis detailed on this paper reveals easy methods to be taught a map that takes a content material code, derived from a face picture, and a randomly chosen type code to an anime picture. An adversarial loss from our easy and efficient definitions of favor and content material is derived. This adversarial loss ensures the map is various — a really big selection of anime will be produced from a single content material code. Beneath believable assumptions, the map isn’t just various, but additionally appropriately represents the chance of an anime, conditioned on an enter face. In distinction, present multimodal era procedures can’t seize the complicated kinds that seem in anime. Intensive quantitative experiments assist the thought the map is appropriate. Intensive qualitative outcomes present that the tactic can generate a way more various vary of kinds than SOTA comparisons. Lastly, the paper reveals that the formalization of content material and elegance makes it attainable to carry out video to video translation with out ever coaching on movies. The GitHub repo related to this paper will be discovered HERE.
This paper introduces a framework that abstracts Reinforcement Studying (RL) as a sequence modeling downside. This makes it attainable to attract upon the simplicity and scalability of the Transformer structure, and related advances in language modeling corresponding to GPT-x and BERT. Particularly, the paper presents Resolution Transformer, an structure that casts the issue of RL as conditional sequence modeling. Not like prior approaches to RL that match worth features or compute coverage gradients, Resolution Transformer merely outputs the optimum actions by leveraging a causally masked Transformer. By conditioning an autoregressive mannequin on the specified return (reward), previous states, and actions, the Resolution Transformer mannequin can generate future actions that obtain the specified return. Regardless of its simplicity, Resolution Transformer matches or exceeds the efficiency of state-of-the-art model-free offline RL baselines on Atari, OpenAI Fitness center, and Key-to-Door duties. The GitHub repo related to this paper will be discovered HERE.
